 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatPhys: Learning Material-Aware Physics Parameters for Deformable Object Simulation from Videos
May 19, 2026Reconstructing simulation-ready deformable objects is important for vision, graphics, and robotics. Existing physics-driven methods can recover physical digital twins from videos, but they suffer from two fundamental limitations: they typically assume a homogeneous material across the whole object, and their scene-specific inverse optimization, combined with the inherent ambiguity of monocular observation, yields inconsistent parameters for the same material across different scenes or interactions. We propose MatPhys, a material-aware feed-forward framework that predicts spring-mass parameters from a single-view video, addressing these two issues with two coupled designs. To relax the homogeneous material assumption, we use DINO features to decompose the object into semantically meaningful parts and to query a part-level material prior, assigning each part its own physical behavior. To enforce cross-scene consistency, we introduce a learned material codebook of shared material embeddings as the bridge between appearance and physics, and further use the part-level prior as a reference distribution that constrains the decoder so that the same material yields consistent parameters across scenes and interactions. Together, these designs turn an under-constrained monocular problem into feed-forward inference grounded on shared, reusable material concepts. Experiments show that our method matches per-scene optimization baselines in reconstruction and future prediction, while achieving stronger generalization to unseen interactions and objects with more consistent physical parameters.
EMAGE: Towards Unified Holistic Co-Speech Gesture Generation via Masked Audio Gesture Modeling
Jan 02, 2024



We propose EMAGE, a framework to generate full-body human gestures from audio and masked gestures, encompassing facial, local body, hands, and global movements. To achieve this, we first introduce BEATX (BEAT-SMPLX-FLAME), a new mesh-level holistic co-speech dataset. BEATX combines MoShed SMPLX body with FLAME head parameters and further refines the modeling of head, neck, and finger movements, offering a community-standardized, high-quality 3D motion captured dataset. EMAGE leverages masked body gesture priors during training to boost inference performance. It involves a Masked Audio Gesture Transformer, facilitating joint training on audio-to-gesture generation and masked gesture reconstruction to effectively encode audio and body gesture hints. Encoded body hints from masked gestures are then separately employed to generate facial and body movements. Moreover, EMAGE adaptively merges speech features from the audio's rhythm and content and utilizes four compositional VQ-VAEs to enhance the results' fidelity and diversity. Experiments demonstrate that EMAGE generates holistic gestures with state-of-the-art performance and is flexible in accepting predefined spatial-temporal gesture inputs, generating complete, audio-synchronized results. Our code and dataset are available at https://pantomatrix.github.io/EMAGE/
BEAT: A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis
Mar 18, 2022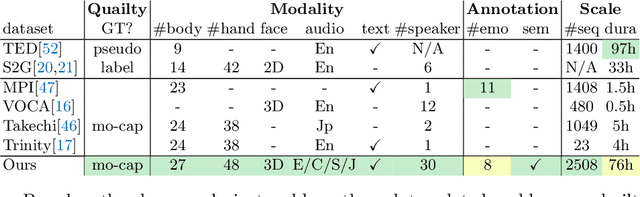
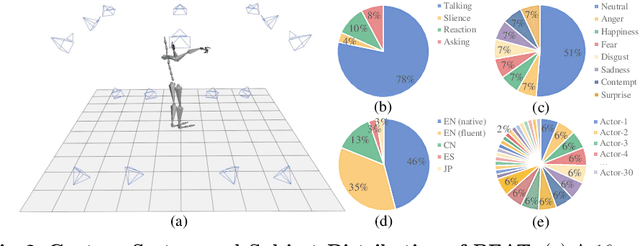

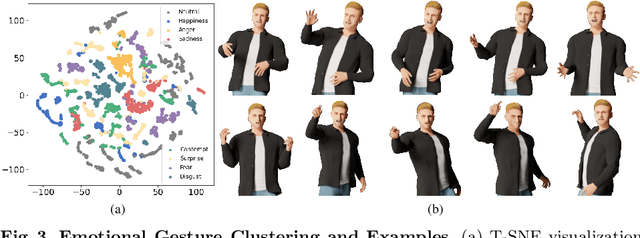
Achieving realistic, vivid, and human-like synthesized conversational gestures conditioned on multi-modal data is still an unsolved problem, due to the lack of available datasets, models and standard evaluation metrics. To address this, we build Body-Expression-Audio-Text dataset, BEAT, which has i) 76 hours, high-quality, multi-modal data captured from 30 speakers talking with eight different emotions and in four different languages, ii) 32 millions frame-level emotion and semantic relevance annotations.Our statistical analysis on BEAT demonstrates the correlation of conversational gestures with facial expressions, emotions, and semantics, in addition to the known correlation with audio, text, and speaker identity. Qualitative and quantitative experiments demonstrate metrics' validness, ground truth data quality, and baseline's state-of-the-art performance. To the best of our knowledge, BEAT is the largest motion capture dataset for investigating the human gestures, which may contribute to a number of different research fields including controllable gesture synthesis, cross-modality analysis, emotional gesture recognition. The data, code and model will be released for research.